Vehicle Recognition
Python
PyTorch

Overview
This project was my Bachelor's dissertation. I set out to tackle Vehicle Make and Model Recognition (VMMR) — essentially teaching a model to identify the exact make and model of a car from an image. The real-world challenge I focused on was: what happens when you only have a handful of training images for a new vehicle? That's the few-shot learning problem, and it's a very real constraint in traffic monitoring, law enforcement, and autonomous systems.
Research Questions
The dissertation revolved around four questions:
- How do established few-shot methods hold up on a vehicle recognition task?
- Does the quality of a part detector actually affect the graph representations built from it?
- What makes it hard to turn 2D vehicle images into useful graph structures?
- What would a better approach look like going forward?
System Architecture
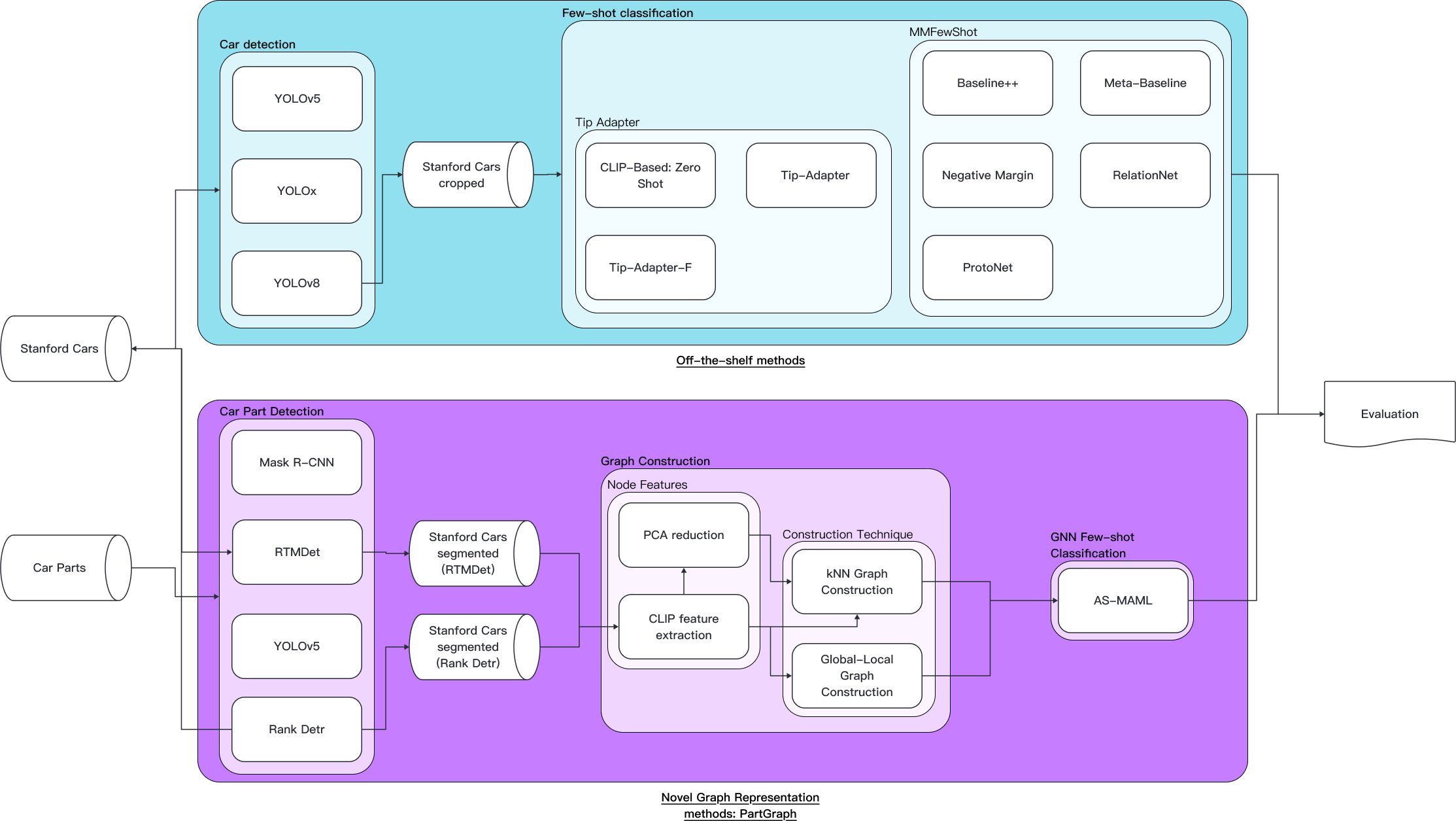
The system has two tracks. The first benchmarks well-known few-shot methods against cropped Stanford Cars images. The second is my own contribution — PartGraph — a pipeline that detects vehicle parts, builds a graph from them, and runs a GNN classifier on top.
Off-the-Shelf Few-Shot Methods
Traditional Meta-Learning
I tested a range of standard meta-learning approaches on Stanford Cars in a 5-way setup:
| Model | 5-way 1-shot | 5-way 5-shot |
|---|---|---|
| Meta-Baseline | — | 38.28 ± 1.91 |
| Baseline++ | 23.92 ± 1.17 | 31.97 ± 1.24 |
| ProtoNet | 27.64 ± 1.33 | 27.51 ± 1.13 |
| ProtoNet + Random Crop | 35.35 ± 1.21 | — |
| RelationNet | 22.03 ± 0.93 | 25.32 ± 1.02 |
| Negative Margin | 23.63 ± 1.11 | 27.97 ± 1.19 |
Adding random crops to ProtoNet made a big difference — jumping from 27.64% to 35.35% on 1-shot. That said, both versions overfit; validation accuracy started dropping past the halfway point of training. Meta-Baseline was skipped for 1-shot due to the training time involved.
CLIP-Based Methods
CLIP-based adapters blew the traditional methods out of the water:
| Shots | Zero-Shot CLIP | Tip-Adapter | Tip-Adapter-F |
|---|---|---|---|
| 5 | 55.64% | 61.98% | 66.35% |
| 8 | 55.64% | 62.93% | 68.93% |
| 12 | 55.64% | 64.87% | 72.94% |
| 16 | 55.64% | 66.75% | 74.97% |
Tip-Adapter-F hit 74.97% at 16-shot — nearly double what ProtoNet managed. The gap between CLIP-based and traditional meta-learning was pretty striking.
PartGraph: My Novel Approach
Car Parts Dataset
For training the part detectors, I used a dataset with 30,772 annotated instances across 21 vehicle part categories:
| Category | Instances | Category | Instances | Category | Instances |
|---|---|---|---|---|---|
| Back Bumper | 909 | Back Door | 1,425 | Back Wheel | 1,677 |
| Back Window | 2,394 | Back Windshield | 574 | Fender | 1,820 |
| Front Bumper | 1,358 | Front Door | 1,779 | Front Wheel | 1,723 |
| Front Window | 1,859 | Grille | 1,079 | Headlight | 1,742 |
| Hood | 1,375 | License Plate | 743 | Mirror | 1,892 |
| Quarter Panel | 1,659 | Rocker Panel | 1,677 | Roof | 1,531 |
| Tail Light | 1,504 | Trunk | 852 | Windshield | 1,200 |
Instance Segmentation Results (Mask mAP)
| Model | mAP | mAP50 | mAP75 | mAPs | mAPm | mAPl |
|---|---|---|---|---|---|---|
| Mask R-CNN | 31.10% | 46.00% | 36.00% | 12.50% | 24.60% | 36.60% |
| RTMDet | 37.90% | 49.50% | 41.00% | 4.60% | 26.20% | 44.80% |
| YOLOv5 | 32.40% | 48.00% | 33.50% | 3.40% | 24.10% | 38.70% |
Segmentation quality was poor across all three models, so I switched to bounding boxes for graph construction instead, as using noisy masks would have just polluted the node features.
Bounding Box Detection Results (mAP)
| Model | mAP | mAP50 | mAP75 | mAPs | mAPm | mAPl |
|---|---|---|---|---|---|---|
| Mask R-CNN | 69.80% | 91.30% | 77.70% | 28.20% | 59.00% | 75.30% |
| RTMDet | 63.70% | 87.20% | 71.20% | 17.20% | 51.30% | 70.00% |
| YOLOv5 | 59.50% | 83.90% | 66.20% | 6.80% | 44.70% | 68.40% |
| Rank-DETR | 76.14% | 94.08% | 83.76% | 45.83% | 64.52% | 83.87% |
Rank-DETR came out on top with 76.14% mAP, making it the strongest candidate for feeding into PartGraph.
Full Results Comparison
| Method | 1-shot | 5-shot | 8-shot | 12-shot | 16-shot |
|---|---|---|---|---|---|
| Traditional Few-Shot (5-way) | |||||
| Meta-Baseline | — | 38.28 | — | — | — |
| Baseline++ | 23.92 | 31.97 | — | — | — |
| ProtoNet | 27.64 | 27.51 | — | — | — |
| ProtoNet + Random Crop | 35.35 | — | — | — | — |
| RelationNet | 22.03 | 25.32 | — | — | — |
| Negative Margin | 23.63 | 27.97 | — | — | — |
| CLIP-Based | |||||
| Zero-Shot CLIP | 55.64 | 55.64 | 55.64 | 55.64 | 55.64 |
| Tip-Adapter | — | 61.98 | 62.93 | 64.87 | 66.75 |
| Tip-Adapter-F | — | 66.35 | 68.93 | 72.94 | 74.97 |
| PartGraph (5-way) | |||||
| CLIP + RTMDet | — | 20.11 | — | — | — |
| CLIP + Rank-DETR | — | 19.89 | — | — | — |
| CLIP + PCA + Rank-DETR | — | 19.77 | — | — | — |
| CLIP + Global-Local + Rank-DETR | — | 19.61 | — | — | — |
| State-of-the-Art (Literature) | |||||
| Liu et al. (2024)* | 91.37 | 98.63 | — | — | — |
| Chen et al. (2020a)* | 73.15 | 91.89 | — | — | — |
| Li et al. (2019)* | 61.51 | 89.60 | — | — | — |
| Li et al. (2023)* | 76.81 | 88.21 | — | — | — |
Taken from literature, not reproduced here.
Key Findings
- CLIP-based adapters are the clear winner for low-data vehicle recognition — Tip-Adapter-F at 74.97% (16-shot) was the standout result
- Graph-based approaches have real fundamental problems to solve: sparse detections, inconsistent part localisation, and vehicle graphs that just don't look that different from one class to another
- The part detector matters a lot — Rank-DETR's better mAP directly produced cleaner graph structures
- PartGraph underperformed, but learning from it's failure gives insight on how to tackle this problem in the future.
Conclusion
The dissertation landed on a strong few-shot baseline for VMMR and introduced a graph-based approach that, while not competitive, demonsstrates a new idea for vehicle recognition.
On this page
Links